1、索引的作用
类似于一本书中的目录,起到优化查询的作用。
2、索引的分类(算法)
B树 默认使用的索引类型
R树 基本上不用
Hash 自适应哈希索引
FullText 全文索引
GIS 索引(地理位置)
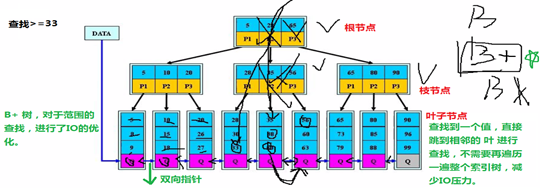
3、BTree 索引算法演变(了解)
B-Tree(最早期的B树)
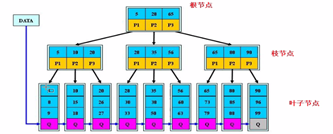
 B+树
B+树
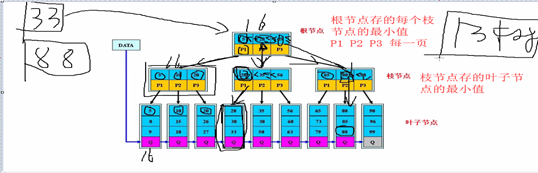
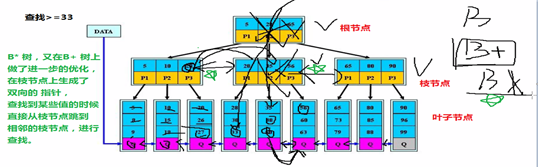
 B*树(现在mysql用的就是这种)
B*树(现在mysql用的就是这种)
 上层节点保存的都是下层节点的最小值,不管根节点、枝节点、叶子节点,每个都是按数据页(每个数据页16K)来存储的,ibd文件里面存储的就是数据行和索引。
4、Btree 索引按功能分类
4.1、辅助索引(需要自己创建)
上层节点保存的都是下层节点的最小值,不管根节点、枝节点、叶子节点,每个都是按数据页(每个数据页16K)来存储的,ibd文件里面存储的就是数据行和索引。
4、Btree 索引按功能分类
4.1、辅助索引(需要自己创建)
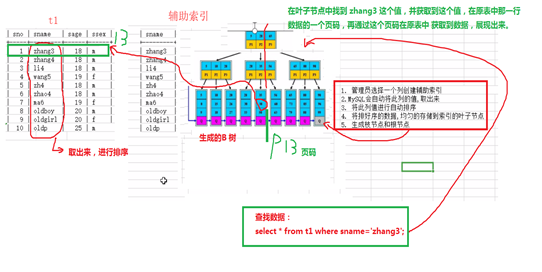 a、提取索引列的所有值,进行排序
b、将排好序的值,均匀的存放在叶子节点,进一步生成枝节点和根节点。
c、在叶子节点中的值,都会对应存储主键ID
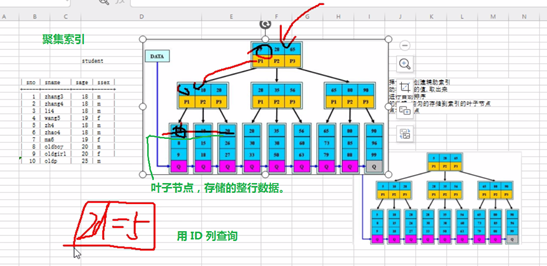
4.2、聚集索引(自动生成)
直接将 整行数据 按照顺序 存储到 叶子 节点当中,上层的枝节点,依然是取的叶子节点列的最小值。
a、Mysql 会自动选择主键作为聚集索引列,如果没有主键,会选择唯一键,如果都没有,会生成隐藏的。
b、Mysql进行存储数据时,会按照聚集索引列的顺序,有序存储数据行。
c、聚集索引直接将原表的数据页,作为叶子节点,然后提取聚集索引列的最小值,往上生成枝节点和根节点。
a、提取索引列的所有值,进行排序
b、将排好序的值,均匀的存放在叶子节点,进一步生成枝节点和根节点。
c、在叶子节点中的值,都会对应存储主键ID
4.2、聚集索引(自动生成)
直接将 整行数据 按照顺序 存储到 叶子 节点当中,上层的枝节点,依然是取的叶子节点列的最小值。
a、Mysql 会自动选择主键作为聚集索引列,如果没有主键,会选择唯一键,如果都没有,会生成隐藏的。
b、Mysql进行存储数据时,会按照聚集索引列的顺序,有序存储数据行。
c、聚集索引直接将原表的数据页,作为叶子节点,然后提取聚集索引列的最小值,往上生成枝节点和根节点。
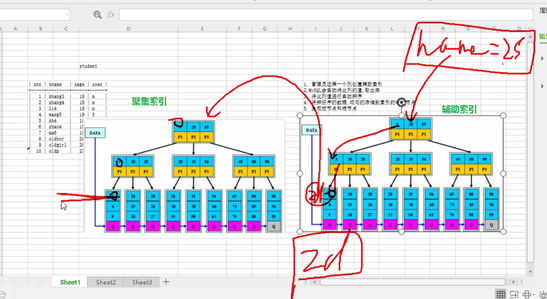 4.3、聚集索引和辅助索引的区别
a、表中任何一个列都可以创建辅助索引,在你有需要的时候,可以创建多个辅助索引,只要名称不同。
b、在一张表中,聚集索引只能有一个,一般是主键。
c、辅助索引,叶子节点,只存储索引列的有序值 + 聚集索引列(主键)值。
d、聚集索引,叶子节点,存储的是有序的整行数据。
e、Mysql 的表数据存储是聚集索引组织表
5、辅助索引细分
5.1、单列辅助索引
5.2、联合索引(覆盖索引),多列,*****
5.3、唯一索引,建索引的列的值是唯一的。
6、索引树高度
索引树高度应当 越低越好,一般维持到 3---4层最佳。
影响索引树高度的因素:
6.1、数据行数较多的时候
分表:parttion (以前用得很多,现在用的很少了。) 从逻辑上拆开
分片,分布式架构(分库分表)。
6.2、字段长度
业务允许,尽量选择字符长度 短 的列作为索引列。
业务不允许,采用前辍索引
6.3、数据类型
char 和 varchar,定长用char,不定长用varcha。
enum,通用enum类型存储的,用enum,比如,省份。
7、索引的命令操作
7.1、查询索引
desc city;
show index from city; 都可以。
4.3、聚集索引和辅助索引的区别
a、表中任何一个列都可以创建辅助索引,在你有需要的时候,可以创建多个辅助索引,只要名称不同。
b、在一张表中,聚集索引只能有一个,一般是主键。
c、辅助索引,叶子节点,只存储索引列的有序值 + 聚集索引列(主键)值。
d、聚集索引,叶子节点,存储的是有序的整行数据。
e、Mysql 的表数据存储是聚集索引组织表
5、辅助索引细分
5.1、单列辅助索引
5.2、联合索引(覆盖索引),多列,*****
5.3、唯一索引,建索引的列的值是唯一的。
6、索引树高度
索引树高度应当 越低越好,一般维持到 3---4层最佳。
影响索引树高度的因素:
6.1、数据行数较多的时候
分表:parttion (以前用得很多,现在用的很少了。) 从逻辑上拆开
分片,分布式架构(分库分表)。
6.2、字段长度
业务允许,尽量选择字符长度 短 的列作为索引列。
业务不允许,采用前辍索引
6.3、数据类型
char 和 varchar,定长用char,不定长用varcha。
enum,通用enum类型存储的,用enum,比如,省份。
7、索引的命令操作
7.1、查询索引
desc city;
show index from city; 都可以。
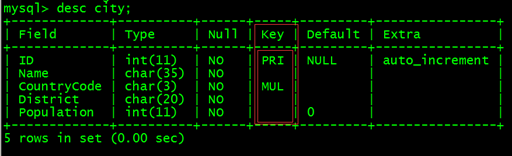
PRI ====> 主键索引
MUL ====> 辅助索引
UNI ====> 唯一索引
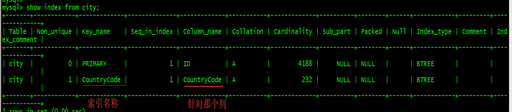 7.2、创建索引
单列索引:
alter table city add index idx_name(name);
#索引名称,可以随意,也是在线的DDL操作,也会锁表。
联合索引:
alter table city add index idx_c_p(countrycode,population);
唯一索引:(判断 列 能不能建唯一索引)
alter table city add unique index uidx_dis(district);
select count(district) from city;
select count(distinct district) from city;
前辍索引:(只能是字符串列)作用,减少key_len:索引覆盖长度
alter table city add index idx_dis(district(5)); #只取前5个,从左到右取。
7.2、创建索引
单列索引:
alter table city add index idx_name(name);
#索引名称,可以随意,也是在线的DDL操作,也会锁表。
联合索引:
alter table city add index idx_c_p(countrycode,population);
唯一索引:(判断 列 能不能建唯一索引)
alter table city add unique index uidx_dis(district);
select count(district) from city;
select count(distinct district) from city;
前辍索引:(只能是字符串列)作用,减少key_len:索引覆盖长度
alter table city add index idx_dis(district(5)); #只取前5个,从左到右取。
alter table city add index idx_dis;

alter table city drop index idx_dis;
alter table city add index idx_qz_dis(district(5));

7.3、删除索引
show index from city;
alter table city drop index idx_name;
8、压力测试:
创建一个测试(test)库,一张表(t100w),插入100万左右的数据
create database test charset utf8mb4;
use test;
create table t100w(id int(11), num int(11),k1 char(2),k2 char(4),dt timestamp not null);
插入数据的脚本
#!/bin/bash
SUSER=root
SPASS="w.....123"
for ((i=1;i<=1030000;i++))
do
num=$RANDOM
Kone=`cat /dev/urandom | head -n 10 | md5sum | head -c 2`
Ktwo=`cat /dev/urandom | head -n 10 | md5sum | head -c 4`
dt=`date +%Y-%m-%d' '%H:%M:%S`
mysql -u$SUSER -p$SPASS -e "insert into test.t100w values('$i','$RANDOM','$Kone','$Ktwo','$dt');" 2>/tmp/test_ins.log
done
echo -e "\033[31m test 库 t1oow 表,插入数据成功。\033[0m"
++++++++++++++++++++++++++
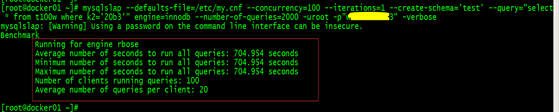
8.1、未做优化之前测试
mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='test' --query="select * from t100w where k2='20b3'" engine=innodb --number-of-queries=2000 -uroot -p"w.....123" -verbose
100个用户连接数据库,做了2000次查询。
从t100w表中,用任意一个k2的值替换上面语句中k2=的值。
--create-schema=name 指定测试的数据库名,默认是mysqlslap
--engine=name 创建测试表所使用的存储引擎,可指定多个,例如:--engines=myisam,innodb,memory
--concurrency=N 模拟N个客户端并发执行。可指定多个值,以逗号隔开,例如:--concurrency=50,200,500
--number-of-queries=N 总的测试查询次数(并发客户数×每客户查询次数),比如并发是10,总次数是100,那么10个客户端各执行10个
--iterations=N 迭代执行的次数,即重复的次数(相同的测试进行N次,求一个平均值),指的是整个步骤的重复次数,包括准备数据、测试load、清理
--query 自定义的sql 命令脚本
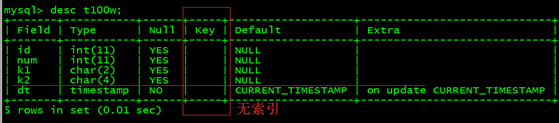 8.2、索引优化后
创建一个索引:
alter table t100w add index idx_ktwo(k2);
8.2、索引优化后
创建一个索引:
alter table t100w add index idx_ktwo(k2);
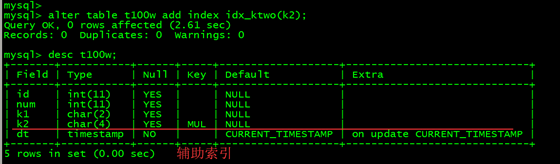 再次进行压力测试:
再次进行压力测试:
 ++++++++++++
++++++++++++