*****6、mongodump和mongorestore高级企业应用(--oplog) 注意:这是replica set或者master/slave模式专用 --oplog (备份的时候需要添加),先拷贝快照,同时备份,在备份这段时间内产生的数据。有点类似于xtrabackup use oplog for taking a point-in-time snapshot 6.1 oplog介绍 在replica set中oplog是一个定容集合(capped collection),它的默认大小是磁盘空间的5%(可以通过--oplogSizeMB参数修改). 存储的是类似于mysql binlog 里面的,以表的形式存储。 位于local库的db.oplog.rs,有兴趣可以看看里面到底有些什么内容。 其中记录的是整个mongod实例一段时间内数据库的所有变更(插入/更新/删除)操作。 当空间用完时新记录自动覆盖最老的记录。 其覆盖范围被称作oplog时间窗口。需要注意的是,因为oplog是一个定容集合, 所以时间窗口能覆盖的范围会因为你单位时间内的更新次数不同而变化。 想要查看当前的oplog时间窗口预计值,可以使用以下命令: mongod -f /mongodb/28017/conf/mongod.conf mongod -f /mongodb/28018/conf/mongod.conf mongod -f /mongodb/28019/conf/mongod.conf mongod -f /mongodb/28020/conf/mongod.conf use local db.oplog.rs.find().pretty() "ts" : Timestamp(1553597844, 1), ##时间,从1970年到现在操作的时间点,一共发生了多少秒。在这一秒钟,发生的第几个操作。 "op" : "n" ##做了什么类型的操作,n,提示 "o" : "i": insert #插入 "u": update #更新 "d": delete #删除 "c": db cmd ## drop 操作,删库,册表,建表(create)的动作都被定义为 c db.oplog.rs.find({"op":"c"}).pretty() use oldguo db.t1.insert({id:1}) use local db.oplog.rs.find({"op":"i"}).pretty()---- oplog到底设置多大才合适?和全备周期有关,至少保留一轮全备周期 test:PRIMARY> rs.printReplicationInfo() configured oplog size: 1561.5615234375MB <--集合大小 log length start to end: 423849secs (117.74hrs) <--预计窗口覆盖时间,基于现在的业务水平,可以存多少小时。 oplog first event time: Wed Sep 09 2015 17:39:50 GMT+0800 (CST) oplog last event time: Mon Sep 14 2015 15:23:59 GMT+0800 (CST) now: Mon Sep 14 2015 16:37:30 GMT+0800 (CST)
建议: 每天备份,或者陋几个小时,备份一次。生产中一般是隔段时间备份一次,至少保留3、4天,每天要做一个备份。 6.2、oplog企业级应用 实现热备,在备份时使用--oplog选项 ----------------------------------------------------- oplog 配合mongodump实现热备 mongodump --port 28017 --oplog -o /mongodb/backup 作用介绍:--oplog 会记录备份过程中的数据变化。会以oplog.bson保存下来
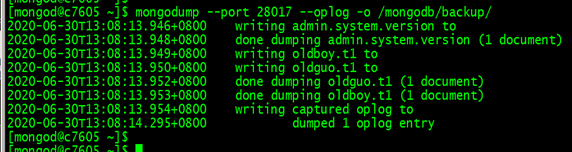
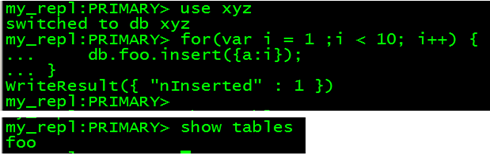
全部恢复: mongorestore --port 28017 --oplogReplay /mongodb/backup mongorestore --port 28017 --drop --oplogReplay /mongodb/backup --drop 删除有重复的表 !!!!!!!!!!oplog高级应用 ==========oplog应用 模拟故障环境: (1)、模拟生产库(mongod用户环境下操作) mongo --port 28017 use xyz for(var i = 1 ;i < 10; i++) { db.foo.insert({a:i}); }
(2)、全备数据库 先清除备份目录下面以前的内容 rm -rf /mongodb/backup/* mongodump --port 28017 --oplog -o /mongodb/backup
--oplog功能: 在备份同时,将备份过程中产生的日志进行备份。 (3)、再次模拟数据写入 db.foo.insert({"a" : 10 }) db.foo.insert({"a" : 11 }) db.foo.insert({"a" : 12 })
(4)、模拟删除xyz 库 use xyz db.dropDatabase()
++++++++++ 恢复数据 (a)、先找到oplog误删除的时间点位置: use local db.oplog.rs.find({"op":"c"}).pretty() "ts" : Timestamp(1593502529, 1)
(b)、备份现有的oplog.rs表 mongodump --port 28017 -d local -c oplog.rs -o /mongodb
将/mongodb/local/oplog.rs.bson 拷贝到 /mongodb/backup/ 并改名oplog.bson cp /mongodb/local/oplog.rs.bson /mongodb/backup/oplog.bson
(c)、恢复备份+应用oplog mongorestore --port 28017 --oplogReplay --oplogLimit "1593502529:1" --drop /mongodb/backup/ (d)、登陆到原数据库,查看恢复的数据。 mongo --port 28017
背景:每天0点全备,oplog恢复窗口为48小时 某天,上午10点world.city 业务表被误删除。 恢复思路: 0、停应用 2、找测试库 3、恢复昨天晚上全备 4、截取全备之后到world.city误删除时间点的oplog,并恢复到测试库 5、将误删除表导出,恢复到生产库 ----------------------------------------- **分片集群的备份思路(了解) 1、你要备份什么? config server ##所有的配置信息 shard 节点 ##所有的分片数据 通过mongos备份出来的数据,是一个整表,只能做单节点恢复。 单独进行备份 2、备份有什么困难和问题 (1)chunk迁移的问题 人为控制在备份的时候,避开迁移的时间窗口。 (2)shard节点之间的数据不在同一时间点。 选业务量较少的时候,最好是节点数据是静止的。 Ops Manager 第三方备份软件 6.5.4 副本集其他操作命令 查看副本集的配置信息 admin> rs.conf() 查看副本集各成员的状态 admin> rs.status() ++++++++++++++++++++++++++++++++++++++++++++++++ --副本集角色切换(不要人为随便操作) admin> rs.stepDown() 注: admin> rs.freeze(300) //锁定从,使其不会转变成主库 freeze()和stepDown单位都是秒。 +++++++++++++++++++++++++++++++++++++++++++++ 设置副本节点可读:在副本节点执行 admin> rs.slaveOk() eg: admin> use app switched to db app app> db.createCollection('a') { "ok" : 0, "errmsg" : "not master", "code" : 10107 } 查看副本节点(监控主从延时) admin> rs.printSlaveReplicationInfo() source: 192.168.1.22:27017 syncedTo: Thu May 26 2016 10:28:56 GMT+0800 (CST) 0 secs (0 hrs) behind the primary