9、执行计划分析 9.1、作用 将优化器 选择后的执行计划 截取出来,便于管理员判断语句的执行效率。 9.2、获取执行计划 desc sql语句 desc select * from city where name= 'Kabul';explain sql语句 explain select * from city where name= 'Kabul'; #获取到的是一样的 9.3、分析执行计划
9.3.1、table #表名 9.3.2、type #查询的类型 全表扫描 : 显示All 索引扫描 :index, range , ref, eq_ref ,const(system), NULL (从左到右,等级超高,性能越好) index:全索引扫描 desc select countrycode from city;
range:索引范围扫描(>, <, >=, <=, between, and, or, in, like) desc select * from city where id >2000;
对于辅助索引来讲,!= 和 not in 等语句是不走索引的。 对于主键索引来讲,!= 和 not in 等语句是走 range
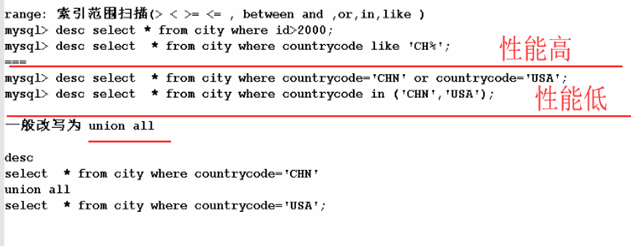
ref:辅助索引等值查询 desc select * from city where countrycode='CHN' union all select * from city where countrycode='USA' eq_ref:多表连接时,子表使用主键或唯一列作为连接条件 A join B on A.x = B.y ##(y列,是B表的主键或者唯一列)
const(system):主键或者唯一键的等值查询 desc select * from city where id=100;
9.3.3、possible_keys: 可能会用到的索引 9.3.4、key:真正选择了那个索引 9.3.5、key_len:索引覆盖长度,作用,判断 联合索引的覆盖长度,一般情况下,越长越好。
utf8mb4 最大的预留长度4 utf8 最大的预留长度3 gbk 最大的预留长度2 varchar(20)----utf8mb4字符集 能存20个任意字符 不管存储的是字符,数字,中文,都1个字符最大预留长度是4个字节 对于中文来讲,1个字符 占4个字节 对于数字和字母,1个字符占用大小是 1 个字节 select length(列) from test;
分别为每列创建一个索引 alter table test add index id(id); alter table test add index k1(k1); alter table test add index k2(k2); alter table test add index k3(k3); alter table test add index k4(k4);
key_len单列:(utf8mb4) 单列,索引长度越小越好 char类型的最大预留长度 + 1(是否允许空,not null 就不加,null 加1) varchar 类型的最大预留长度 + 3(其中1,为null,保留,还有,开始:1,结束:1)




删除刚才创建的索引,重新创建一个联合索引。 alter table test drop index id; alter table test drop index k1; alter table test drop index k2; alter table test drop index k3; alter table test drop index k4; alter table test add index idx(k1,k2,k3,k4); 联合索引:索引长度越大越好,越大说明用的索引越多。
联合索引应用细节:add index idx(a,b,c,d),第一个索引必须要存在 只要我们将来的查询,所有索引列都是等值查询条件下,无关排列顺序。原因是,优化器,会自动做查询条件的排列。唯一值多的列放在最左侧,这样会过滤掉大部分的数据。 不连续的部分条件(但是,第一个索引[最左列]必须要在,如果不在,则不会走索引。) 在条件查询中没有最左列条件时,没有k1的查询,都是不走索引的,就是,你建立索引的时候,比如idx(k1,k2,k3,k4),查询条时,where 条件中,只有(k2,k3,k4),这样是不会走索引的。 cda------>(重新排列)acd ---->a (只走a的索引)-----优化(建索引 idx(c,d,a))
dba------>(重新排列)abd-----ab (只走ab的索引)-----优化(建索引 idx(d,b,a))
3、在where 查询中如果出现> < >= <= like 此类的查询条件。 desc select * from test where k1='aa' and k2>'中国' and k3='aaaa' and k4='中国你好';
怎么优化上面语句: 删除原来的索引 alter table test drop index idx; 重新创建一个索引 alter table test add index idx2(k1,k3,k4,k2); 把 >的条件放在最后 desc select * from test where k1='aa' and k3='aaaa' and k4='中国你好' and k2>'中国';
4、多子句(有group by 有order by)查询,应用联合索引 desc select * from test where k1='aa' order by k2; alter table test add index idx3(k1,k2);

必须按照子句的执行顺序去建联合索引 9.3.6、extra: 重点关注 Using filesort(还需要额外的文件排序) 出现: Using filesort,说明在查询中有关排序的条件列没有合理应用索引。 (order by 、group by、distinct、union)会出现排序。关注key_len应用的长度,有没有走全。 explain(desc)使用场景(面试题) 你做过哪些优化? 你作过什么优化工具? 你对索引这块怎么优化的? 我们公司业务慢,请你从数据库的角度分析原因 mysql 出现性能问题,我总结有两种情况 a)、应急性的慢:突然夯住 应急情况:数据库hang(卡了,资源耗尽) 处理过程: show processlist; 获取到导致数据库hang的语句 explain 分析 sql 的执行计划,有没有走索引,索引的类型情况 建索引,修改语句。 如果还是卡,考虑有可能是语句本身的问题,需要开发配合修改。 b)、一段时间慢(持续性的): 记录慢日志slowlog,分析slowlog 。 explain 分析 sql 的执行计划,有没有走索引,索引的类型情况 建索引,修改语句。 ++++++++++++++++++++ 索引应用规范: 建立索引的原则(DBA运维规范) (1)、建表必须要有主键,一般是无关列,自增长。 (2)、经常做为where 条件列 order by group by join on,distinct 的条件列建索引 (3)、最好使用唯一值多的列作为联合索引前导列,其他的按照联合索引优化细节来做。 (4)、列值长度较长的索引列,我们建议使用前辍索引。减少key_len:索引覆盖长度 (5)、降低索引条目,不要创建没有用的索引,不常使用的索引清理,sqlyog,表信息,找出多余索引 (6)、索引维护要避开业务繁忙期 (7)、小表(几百行,几千行)不建索引 不走索引的情况(开发规范) (1)、没有查询条件,或者查询条件没有建立索引 select * from city; select * from city where 1=1; (2)、查询结果集是原表中的大部分数据,应该是25%以上。 查询结果集超过原表中25%的数据,不走索引。 (3)、索引本身失效,统计数据不真实。(大量的对索引列更新数据) 面试题:同一个语句突然变慢? 统计信息过旧,导致的索引失效。 (4)、查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,!)等。 where 后面的条件 有计算 不走索引
(5)、隐式转换导致索引失效
(6)、< >,not in 不走索引(辅助索引) (7)、like "%aa" 百分号在最前面不走索引