ES集群: 1.多台机器 2.处于同一个组里 准备两台服务器,都安装好elasticsearch 本次实验环境: elk01 192.168.189.118 节点名称:node-1 elk02 192.168.189.119 节点名称:node-2 +++++++ 修改配置文件: vim /etc/elasticsearch/elasticsearch.ymlvim----> 小技巧,快速删除符号(双引号,中括号)内里的内容 在默认模式下,光标定位到第一个符号上,按 di + 第一个符号, 比如,删除双引号里面的内容,定位到第一个双引号,按di键盘上的双引号,就可以快速删除。
master-eligible nodes(可能成为主节点的节点数) / 2 + 1 公式就是:(可能成为主节点的节点数/2) + 1 集群---->副本,设计到一个选举,至少要大多数同意,一般这种集群,节点数都是奇数。
保存,退出。重启elasticsearch +++++++++++++ 集群配置文件说明: grep "^[a-z]" elasticsearch.yml cluster.name: Linux #集群名称,同一个集群内所有节点集群名称要一模一样 node.name: node-1 #节点名称,同一个集群内所有节点的节点名称不能重复 path.data: /data/elasticsearch #数据目录 path.logs: /var/log/elasticsearch #日志目录 bootstrap.memory_lock: true #内存锁定 network.host: 10.0.0.51,127.0.0.1 #绑定监听地址 http.port: 9200 #默认端口号 discovery.zen.ping.unicast.hosts: ["192.168.189.118", "192.168.189.119"] #集群发现节点配置 discovery.zen.minimum_master_nodes: 2 #选项相关参数,有公式 master/2 +1 ++++++++++++ tail -f /var/log/elasticsearch/linuxes.log ## 这时候的日志,不再是elasticsearch.log,而是我们在配置文件里面配置的集群名称.log ++++++++++++++++++++++ 修改第二台服务器192.168.189.119的配置: 直接把第一台189.118的配置文件拷贝过去,进行修改。 ##(在 189.118上拷贝配置文件到119) scp /etc/elasticsearch/elasticsearch.yml root@192.168.189.119:/etc/elasticsearch/ vim /etc/elasticsearch/elasticsearch.yml ##(在189.119上面操作)

重启elasticsearch systemctl restart elasticsearch.service ##189.119上重启 查看 日志:
这时再看 189.118上面的日志,
集群正常了。
集群状态颜色: 绿色: 所有条件都满足,数据完整,副本满足 黄色: 数据完整,副本不满足 红色: 有索引里的数据出现不完整了 紫色: 有分片正在同步中 查看集群信息:
节点角色: 主节点 :负责调度数据,返回数据。 工作节点 :负责处理数据 默认情况下: 1、所有节点都是工作节点 2、主节点即负责调度又负责处理数据 操作指令: curl -XGET 'http://192.168.189.118:9200/_nodes/procese?human&pretty'
curl -XGET 'http://192.168.189.118:9200/_nodes/_all/info/jvm,process?human&pretty' 打印节点的所有信息,很详细。 curl -XGET 'http://192.168.189.118:9200/_cluster/health?pretty' ## 查看集群健康信息: { "cluster_name" : "linuxes", "status" : "green", "timed_out" : false, "number_of_nodes" : 2, "number_of_data_nodes" : 2, "active_primary_shards" : 5, "active_shards" : 10, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 } curl -XGET 'http://192.168.189.118:9200/_cat/indices?pretty' 查询集群中有那些索引
curl -XGET 'http://192.168.189.118:9200/_cat/nodes?human&pretty' 打印当前集群节点数
问题1: 2个节点,master设置为2的时候,一台出现故障会导致集群不可用 解决方案: 把还存活的节点的配置文件集群选举相关的选项注释掉或者改成1 discovery.zen.minimum_master_nodes: 1 重启elasticsearch服务 两边没有配置这个参数:discovery.zen.minimum_master_nodes 当网络发生抖动时,会出现脑裂。 集群出现脑裂:(两边成为独立的集群) 恢复时: 两个节点数据不一致会导致查询结果不一致 找出不一致的数据,清空一个节点,以另一个节点的数据为准 然后手动插入修改后的数据 ++++++++++++++++++++++ 增加第三台节点:(192.168.189.120 主机名:elk03 节点名称:node-3) 新增节点配置步骤: 1、安装好软件 rpm -ivh elasticsearch-6.6.0.rpm 2、修改配置文件 vim /etc/elasticsearch/elasticsearch.yml cluster.name: linuxes node.name: node-3 path.data: /data/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true network.host: 192.168.189.120 http.port: 9200 discovery.zen.ping.unicast.hosts: ["192.168.189.118", "192.168.189.120"] discovery.zen.minimum_master_nodes: 2 +++++++++注意: discovery.zen.ping.unicast.hosts: ["192.168.189.118", "192.168.189.120"] 只需要填写,集群中任意一台节点地址,和自己的地址,就可以了。因为整个集群中的信息都是共享的,连接一台,也就能知道其他节点信息。 discovery.zen.minimum_master_nodes: 2 根据公式:master-eligible nodes(可能成为主节点的节点数) / 2 + 1 3/2 + 1 =2.5 取整数 ++++++++ 重启elasticsearch 查看日志: tail -f /var/log/elasticsearch/linuxes.log
192.168.189.118 上面: tail -f /var/log/elasticsearch/linuxes.log
++++++++++++++ 默认数据分配: 5分片 1副本
停掉:192.168.189.118 主节点的elasticsearch systemctl stop elasticsearch
+++++++ 这时,再把node-3 192.168.189.120 的ES 关掉 看集群是否能正常启动 [root@elk03 ~]# systemctl stop elasticsearch.service
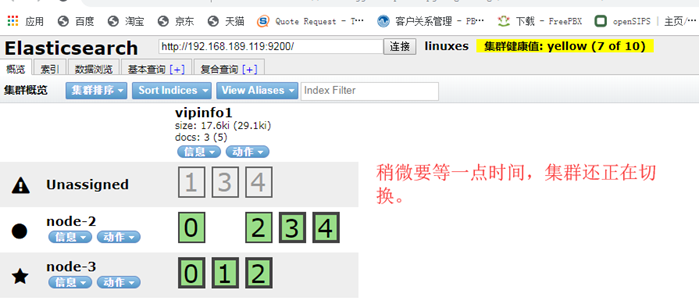
发现集群挂掉了, 这是因为集群配置文件中的这个参数:discovery.zen.minimum_master_nodes: 2 现在只剩下一个节点了,不够节点数,所以集群不能启动了。 189.119 上面查看日志,就会发现: tail -f /var/log/elasticsearch/linuxes.log
这时,修改 189.119 上面的配置文件,把discovery.zen.minimum_master_nodes: 2 改为 1 重启 elasticsearch systemctl restart elasticsearch.service
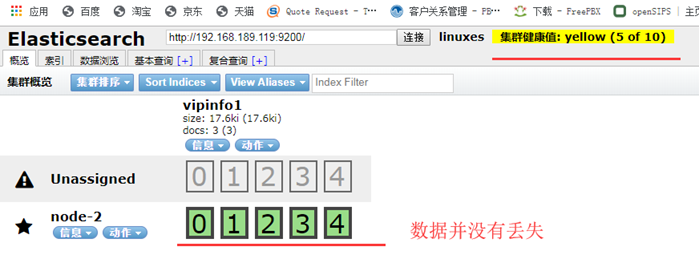
+++++++++++ 这时,把其他两个节点(189.118、189.120)的数据,删除。 rm -rf /data/elasticsearch/* systemctl start elasticsearch.service
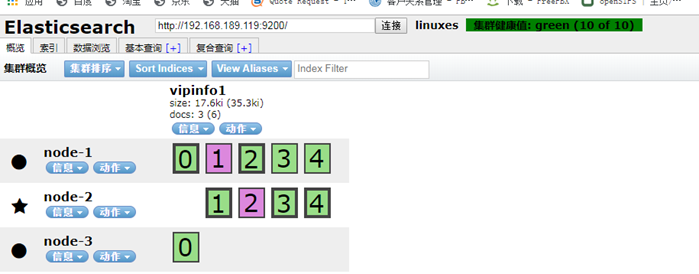
一个集群,三个节点,极限是可以坏两个节点,但是不能同时坏。 +++++++ 同时,关闭两个节点: systemctl stop elasticsearch
要解决这个问题,要启动几台节点,这取决于,你丢的数据是在那一个节点 启动 189.118 上面的es -----------> systemctl start elasticsearch
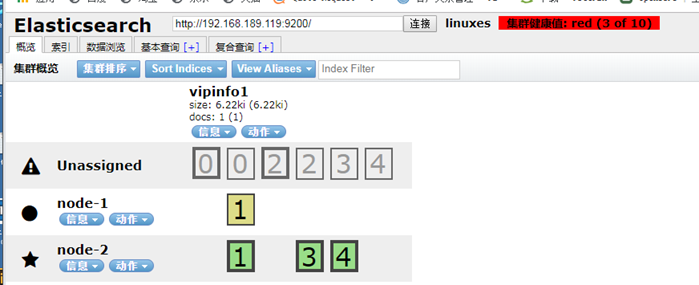
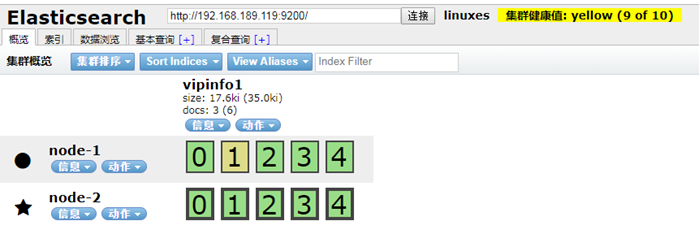
这时虽然集群是好的,但是,丢失了一个节点,所以监控的时候,不能只监控,集群的状态,还应该监控的节点数。 监控leasticsearch: 1、监控集群健康状态 不是 green or [两个节点,只需要满足一个,就要报警,才对。] 2、监控集群节点数量 不是 3(总的节点数) curl -s -XGET 'http://192.168.189.118:9200/_cat/nodes?human&pretty'|wc -l
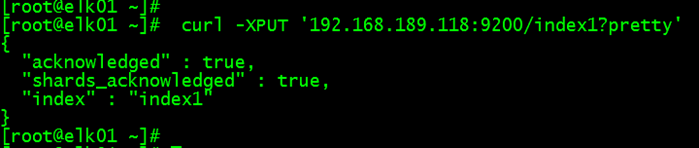
最后,把189.119的discovery.zen.minimum_master_nodes: 1 改为 2 重启elasticsearch ++++++++++++++ 集群分片与复制 默认创建数据: curl -XPUT '192.168.189.118:9200/index1?pretty'
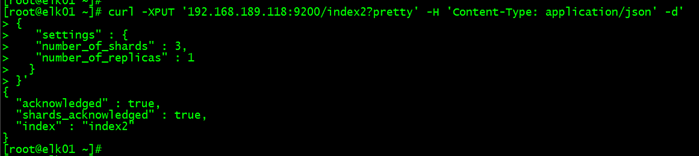
创建索引的时候指定分片和副本 curl -XPUT '192.168.189.118:9200/index2?pretty' -H 'Content-Type: application/json' -d' { "settings" : { "number_of_shards" : 3, "number_of_replicas" : 1 } }'
分片数一旦创建就不能再更改了,但是我们可以调整副本数 curl -XPUT '192.168.189.118:9200/index2/_settings?pretty' -H 'Content-Type: application/json' -d' { "settings" : { "number_of_replicas" : 2 } }'

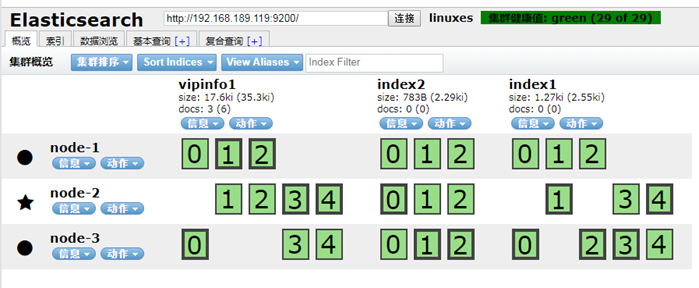
分片多,对于读来说,速度快,磁盘空间占用得大一些。 分片少,对于读来说,速度慢一些,磁盘占用空间少一些。 ++++ 此时集群的状态是绿色的,正常的,
我们这时,将node-1 192.168.189.118 的elasticsearch 关掉,集群状态 会是什么颜色?

为什么集群状态是黄色? 集群状态为黄色表示:数据完整,副本不满足 因为我们刚才创建的索引 index2 ,副本调整为 两个了,现在node-1 es 关掉了,就少了一个副本,所以集群状态颜色变成了黄色。 这时集群的数据并没有丢失,那把集群状态 的颜色改为绿色,应该如何操作? 我们可以调整索引index2的副本数为1,即可。 在node-2 189.119 或者 node-3 189.120 上面都可以修改index2的副本 curl -XPUT '192.168.189.119:9200/index2/_settings?pretty' -H 'Content-Type: application/json' -d' { "settings" : { "number_of_replicas" : 1 } }'

我们再将index2的副本,改为2,再把关掉的node-1 189.118 es 启动起来,让集群恢复正常。