elasticsearch本身就是java开发的,所以我们可以直接收集ES的日志 189.118 --->elk01 安装有 es filebeat kibana 修改filebeat 配置文件,在添加如下内容。 vim /etc/filebeat/filebeat.yml ### filebeat.inputs: 模块下面 - type: log enabled: true paths: - /var/log/elasticsearch/elasticsearch.log tags: ["es"]### output.elasticsearch: 下面 - index: "es-java-%{[beat.version]}-%{+yyyy.MM}" when.contains: tags: "es"
保存,退出,重启filebeat 查看ES数据
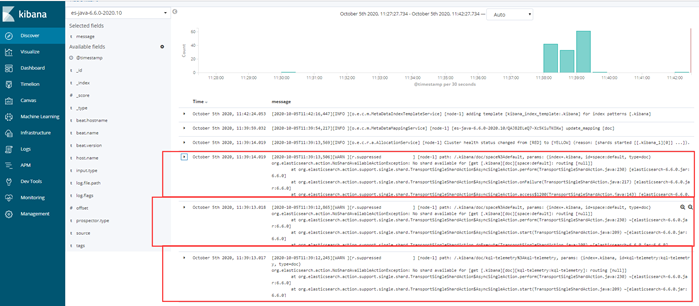
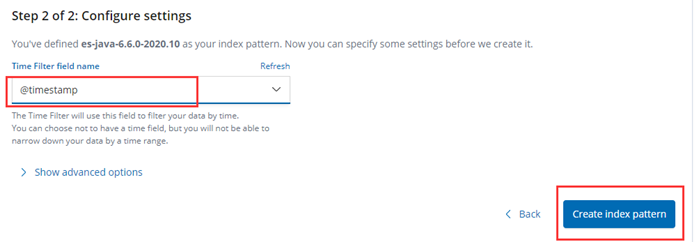
登录Kibana 创建索引数据



往下看,你会发现问题:
在189.118 上面查看elasticsearch 日志 tail -fn 100 /var/log/elasticsearch/elasticsearch.log
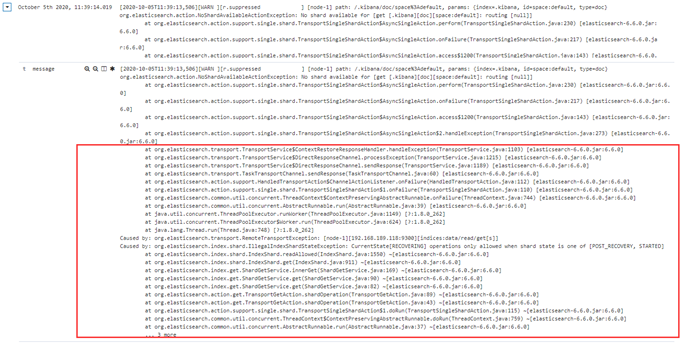
这一些 at 开头的好多行,其实是一个报错,但是在filebeat 收集的时候,当成了多行日志进行收集。 这显然不是我们想要的结果,我们想要的结果,就是这一些at开头的和上面最近一次日期记录的日志,收集起来是被当成一条记录的,如何解决这个问题啦? 可以用filebeat 的多行匹配, 比如,匹配以时间开头, filebeat先匹配这个模式,是不是时间开头,如果是,先标识起来,但是这时它不会发送给elasticsearch,它会继续往下读取,如果下一行不是以时间开头的,把这一行缓存到上一条里面,再继续往下读,直到读到下一行,以日期开头为止,把它中间这些累加的这些信息,当成一条,发送给elasticsearch。 ++++++++++ 官方文档实例: https://www.elastic.co/guide/en/beats/filebeat/6.6/multiline-examples.html
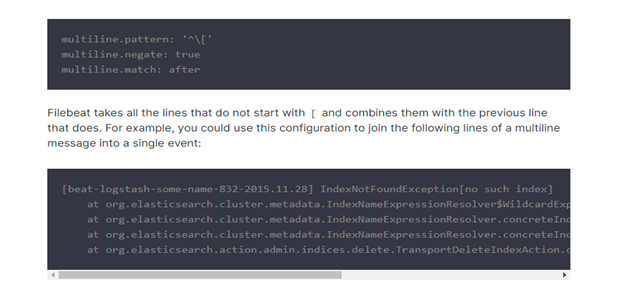
先以b 匹配, 如果不是 b ,就放到缓存里面,再继续匹配,如果还不是 b,继续放到缓存里面,直到匹配到以b开头的为止,把上一个b,到下一个b,中间的当成一条记录。 +++++++++++ 再次修改 filebeat 的配置文件 vim /etc/filebeat/filebeat.yml
保存,退出。 注意:multiline.parttern 这几行是和上面的paths对齐的。 删除 ES中的 es-java索引
清空kibana 里面的es-java索引数据 重启filebeat 服务。systemctl restart filebeat 查看ES里面的数据,你会发现只有很少的几条,没有错误日志。

这时,我们可以手动,造一些错误日志,修改elasticsearch的配置文件,任意加入一点内容,重启elasticsearch 就会产生错误日志,再改回来,再重启elasticsearch 。
登录Kibana ,创建新的es-java索引数据