3. 数据库分布式架构方式 3.1 垂直拆分 不破坏表结构的情况下进行拆分,把多个业务表,拆分到多个数据库实例中,这样,在访问的时候,就是多台服务器来承载所有的读写压力,会缓存写压力集中的情况,这样有一个问题,如果这些表有join 的话,就不能跨库join,所以我们需要一个软件,就是,中间件,来解决。mycat 要做到的是:访问mycat 的时候,虽然物理上拆分了,但是,就跟还在一起一样,需要把后端的表集中起来,然后就跟查同一个库一样,包括跨节点join 。 3.2 水平拆分:(真正体现在业务上面) 垂直拆分还有一个问题,你拆分出来的表,其中并不是所有的表,业务量都很大,有可能只是其中的一张表或多张表业务量大,我们再对业务量大的表,再次拆分成多个表,这就是水平拆分。
range(范围,按ID列),按照每个列的值,进行拆分。比如1亿行的表,折成5个,每2000万一个,仅仅是在数据量级上进行了拆分,并没有考虑真正的业务上,到底数据分布,够不够均匀。 取模: 枚举: hash:是最均匀的,算法最复杂的,性能上会有一定的影响。 时间:按月,按年,特定的时间,等等。 4. Mycat基础应用 4.1 主要配置文件介绍 logs目录: wrapper.log ---->mycat启动日志 mycat.log ---->mycat详细工作日志 conf目录: schema.xml ***** 主配置文件(读写分离、高可用、分布式策略定制、节点控制) server.xml *** ,mycat服务有关,默认用户名和密码root---123456 mycat软件本身相关的配置 rule.xml *****,分片策略定义 分片规则配置文件,记录分片规则列表、使用方法等 log4j2.xml *** ,记录日志有关 *.txt ,分片策略使用的规则 +++++++++++++++ 4.2 用户创建及数据库导入,(为后面的案例做准备)。 db01: world库备份文件下载地址: http://106.12.88.74/softdown/centos7/03_mysql/world.sql mysql -S /data/3307/mysql.sock grant all on *.* to root@'192.168.%' identified by '123'; source /root/world.sql mysql -S /data/3308/mysql.sock grant all on *.* to root@'192.168.%' identified by '123'; source /root/world.sql 4.3 配置文件结构介绍(这里面的name 名称,都可以随意定义。) 192.168.189.128 mycat 服务器 cd /usr/local/mycat/conf mv schema.xml schema.xml.bak vim schema.xml <?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> 前三行是头格式,可以不用去看。 ## mycat 的 逻辑库定义: <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="sh1"> ## 逻辑的,名称可以随便 </schema> ================================================== 数据节点定义: <dataNode name="sh1" dataHost="oldguo1" database= "world" /> ## world 库,是后端真实的库 ==================================================
后端主机定义: <dataHost name="oldguo1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1"> <heartbeat>select user()</heartbeat> <writeHost host="db1" url="192.168.189.99:3307" user="root" password="123"> ## 写节点 <readHost host="db2" url="192.168.189.99:3309" user="root" password="123" /> ##读节点 ##读节点可以写多个,就是写多行。 </writeHost> </dataHost> </mycat:schema> 4.4 mycat实现1主1从读写分离 mycat 服务器(192.168.189.128)上面操作: cd /usr/local/mycat/conf mv schema.xml schema.xml.bak vim schema.xml <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="sh1"> </schema> <dataNode name="sh1" dataHost="oldguo1" database= "world" /> <dataHost name="oldguo1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1"> <heartbeat>select user()</heartbeat> <writeHost host="db1" url="192.168.189.99:3307" user="root" password="123"> <readHost host="db2" url="192.168.189.99:3309" user="root" password="123" /> </writeHost> </dataHost> </mycat:schema> mycat start ###启动 mycat

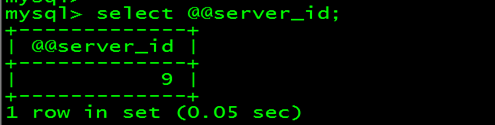
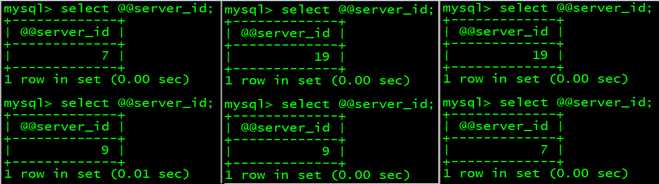
4.5 Mycat高可用+读写分离 mycat 服务器(192.168.189.128)上面操作: cd /usr/local/mycat/conf mv schema.xml schema.xml.1 vim schema.xml <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="sh1"> </schema> <dataNode name="sh1" dataHost="oldguo1" database= "world" /> <dataHost name="oldguo1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1"> <heartbeat>select user()</heartbeat> <writeHost host="db1" url="192.168.189.99:3307" user="root" password="123"> <readHost host="db2" url="192.168.189.99:3309" user="root" password="123" /> </writeHost> <writeHost host="db3" url="192.168.189.131:3307" user="root" password="123"> <readHost host="db4" url="192.168.189.131:3309" user="root" password="123" /> </writeHost> </dataHost> </mycat:schema> 说明: <writeHost host="db1" url="192.168.189.99:3307" user="root" password="123"> <readHost host="db2" url="192.168.189.99:3309" user="root" password="123" /> </writeHost> <writeHost host="db3" url="192.168.189.131:3307" user="root" password="123"> <readHost host="db4" url="192.168.189.131:3309" user="root" password="123" /> </writeHost> 第一个 whost: 192.168.189.99:3307 真正的写节点,负责写操作 第二个 whost: 192.168.189.131:3307 准备写节点,负责读,当 192.168.189.99:3307宕掉,会切换为真正的写节点 重启mycat : mycat restart 测试: [root@db01 conf]# mysql -uroot -p123456 -h 192.168.189.128 -P 8066 读: mysql> select @@server_id;
写: mysql> begin ;select @@server_id; commit;
高可用测试: 在db01 192.168.189.99 上面停掉mysqld3307 systemctl stop mysqld3307 再次测试,读和写

再在 db01 192.168.189.99 上面,启动mysqld3307 systemctl start mysqld3307 这时,修复好的 mysqld3307(server_id 7),就只能是standby master (备主),再这里面,充当从节点,读。
4.6 配置中的属性介绍: <dataHost name="oldguo1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1"> <heartbeat>select user()</heartbeat> <writeHost host="db1" url="192.168.189.99:3307" user="root" password="123"> <readHost host="db2" url="192.168.189.99:3309" user="root" password="123" /> </writeHost> balance属性 负载均衡类型,目前的取值有3种: 1. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上。 2. balance="1",全部的readHost与standby writeHost参与select语句的负载均衡,简单的说, 当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡。 3. balance="2",所有读操作都随机的在writeHost、readhost上分发。就是,write host 那台服务器,也参与读,其他读服务器,不变。 writeType属性,默认为0 负载均衡类型,目前的取值有2种: 1、writeType="0",所有写操作发送到配置的第一个 writeHost, 第一个挂了切到还生存的第二个writeHost,重新启动后,以切换后的为主,切换记录在配置文件中:dnindex.properties . 2. writeType="1",所有写操作都随机的发送到配置的writeHost,但不推荐使用,会出现冲突,以及性能也不见得提高。 switchType属性:当主库down机后,是否进行切换。 -1 表示不自动切换 1 默认值,自动切换 2 基于MySQL主从同步的状态决定是否切换 ,心跳语句为 show slave status datahost其他配置 <dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1"> maxCon="1000":最大的并发连接数 minCon="10" :mycat在启动之后,会在后端节点上自动开启的连接线程 tempReadHostAvailable="1" ,默认情况下,主库down了,它后面的从库,也不能用了 这个参数,可以设置,临时允许从库可继续读, 可能会出现,读取不一致,因为,这个主库后面的从库,已经不能更新数据了,就算读的话,也只能是一些历史数据了, 在四个节点组成的结构中,这个参数也不用加,默认也没有加。 这个一主一从时(1个writehost,1个readhost时),可以开启这个参数,如果2个writehost,2个readhost时 <heartbeat>select user()</heartbeat> 监测心跳 sqlMaxLimit="100" ### 100行做一个分页,可以调整。